Hadoop的概念随着大数据时代浪潮的到来,已经变得不那么陌生,在实际应用中,如何为Hadoop集群选择合适的硬件成为很多人开始使用Hadoop的一个关键问题。
在过去,大数据处理主要是采用标准化的刀片式服务器和存储区域网络(SAN)来满足网格和处理密集型工作负载。然而随着数据量和用户数的大幅增长,基础设施的需求已经发生变化,硬件厂商必须建立创新体系,来满足大数据对包括存储刀片,SAS(串行连接SCSI)开关,外部SATA阵列和更大容量的机架单元的需求。即寻求一种新的方法来存储和处理复杂的数据,Hadoop正是基于这样的目的应运而生的。Hadoop的数据在集群上均衡分布,并通过复制副本来确保数据的可靠性和容错性。因为数据和对数据处理的操作都是分布在服务器上,处理指令就可以直接地发送到存储数据的机器。这样一个集群的每个服务器器上都需要存储和处理数据,因此必须对Hadoop集群的每个节点进行配置,以满足数据存储和处理要求。
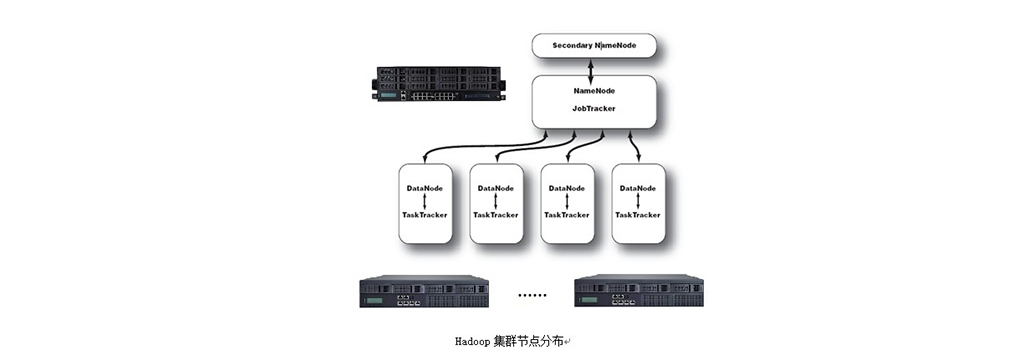
Hadoop框架中最核心的设计是为海量数据提供存储的HDFS和对数据进行计算的MapReduce。MapReduce的作业主要包括从磁盘或从网络读取数据,即IO密集工作,或者是计算数据,即CPU密集工作。Hadoop集群的整体性能取决于CPU、内存、网络以及存储之间的性能平衡。因此运营团队在选择机器配置时要针对不同的工作节点选择合适硬件类型。一个基本的Hadoop集群中的节点主要有:Namenode负责协调集群中的数据存储,DataNode存储被拆分的数据块,Jobtracker协调数据计算任务,最后的节点类型是Secondarynamenode,帮助NameNode收集文件系统运行的状态信息。
在集群中,大部分的机器设备是作为Datanode和TaskTracker工作的。Datanode/TaskTracker的硬件规格可以采用以下方案:
4个磁盘驱动器(单盘1-2T),支持JBOD
2个4核CPU,至少2-2.5GHz
16-24GB内存
千兆以太网
Namenode提供整个HDFS文件系统的namespace管理,块管理等所有服务,因此需要更多的RAM,与集群中的数据块数量相对应,并且需要优化RAM的内存通道带宽,采用双通道或三通道以上内存。硬件规格可以采用以下方案:
8-12个磁盘驱动器(单盘1-2T)
2个4核/8核CPU
16-72GB内存
千兆/万兆以太网
Secondarynamenode在小型集群中可以和Namenode共用一台机器,较大的群集可以采用与Namenode相同的硬件。考虑到关键节点的容错性,建议客户购买加固的服务器来运行的Namenodes和Jobtrackers,配有冗余电源和企业级RAID磁盘。最好是有一个备用机,当 namenode或jobtracker 其中之一突然发生故障时可以替代使用。
目前市场上的硬件平台满足Datanode/TaskTracker节点配置需求的很多,,据了解深耕网络安全硬件平台多年的立华科技瞄准了Hadoop的发展前景,适时推出了专门针对NameNode的设备----双路至强处理器搭载12块硬盘的FX-3411,将计算与存储完美融合,四通道内存的最大容量可达到256GB,完全满足NameNode对于一个大的内存模型和沉重的参考数据缓存组合的需求。
同时在网络方面,FX-3411支持的2个PCI-E*8的网络扩展,网络吞吐达到80Gbps,更是远远满足节点对千兆以太网或万兆以太网的需求。此外针对Datanode/TaskTracker等节点的配置需求,立华科技不仅推出了可支持单路至强E3 8核处理器和4块硬盘的标准品FX-3210,还有可以全面客制化的解决方案,以满足客户的不同需求。
Hadoop集群往往需要运行几十,几百或上千个节点,构建匹配其工作负载的硬件,可以为一个运营团队节省可观的成本,因此,需要精心的策划和慎重的选择。